S3 Security
Introduction
The Amazon Simple Storage Service, commonly referred to as S3, is a serverless, object storage service that promises unrivaled scalability, availability, security, and performance. The official sales pitch states that, regardless of customer or industry, users can safely store any amount of data, for any use case. As such, many configuration options are available that allow users to optimize cost, security and meet their business and compliance needs. Sounds great on paper, but the drawback of offering such flexibility is risk. These options, useful as they are, potentially open many vulnerabilities to attack vectors and it’s clear, from many media sources, that S3 users are not following best practices.
In July 2020, Twilio released an incident report describing an unauthorized modification to one of their platform’s Javascript libraries, hosted on S3. Twilio openly admitted that they had committed a cardinal sin by configuring one of their buckets to allow unrestricted, public, read and write access. This allowed an attacker to anonymously replace a production file, with a modified version, that loaded an extraneous URL in the users browser. They also admitted, that after a further review, they had found a number of other buckets with the same misconfiguration.
In January 2021, security researcher Aaron Phillips released details of lapses in Sega Europe’s cloud security that would have given even the most hardened DevSecOp engineer nightmares. Many sensitive files were stored in a publicly accessible bucket, including files containing active AWS, MailChimp and Steam API Keys. The compromised bucket contained PII, hashed password files, and had the ability to grant access to a varied and dizzying selection of user data.
It is true that cybersecurity is an evolving practice. But by following fundamental best practices and staying up to date with emerging threats and solutions, concerned professionals can rest easy in the knowledge that their data is safe. This article introduces a number of effective S3 best practices, taken directly from the field, that will help you rest easy as well. The executive summary below highlights the key topics that we will cover, so feel free to skip ahead, or read from the beginning.
Executive summary
| Baseline security | Essential first steps in securing your S3 bucket |
| Principles of least privilege | Providing the right level of access to the right actors |
| Access monitoring | Store and understand how your data is being accessed and used |
| Object sensitivity & encryption | Know and protect your data |
| Bucket structure | How to maximize S3 allowances and leverage good structure practices |
| A human touch | Manual auditing & Infrastructure as Code |
The path to improved security
The following sections are not intended to act as a comprehensive guide to every service and configuration available to S3 users, but rather as a pragmatic advisory for improving the overall security of your organization's storage buckets.
Baseline security
Access policies for S3 assets are highly configurable and may allow users to define settings and permissions that unwisely, allow un-restricted public access. Therefore, a good first step is to configure S3 Block Public Access. This feature provides centralized controls that limit public access. Buckets, accounts and access points with S3 Block Public Access settings applied will reject unauthorized public access requests.
Although there are legitimate reasons for providing a degree of public access (hosting a static website for example), it is best practice to lock systems down by default and then allow access on a case by case basis. Tools such as AWS Config or AquaSec can be used to continuously scan and alert to any S3 buckets that allow public read and/or write.
Principles of least privilege
When considering S3 access levels, it’s important not to focus on public access concerns only. Individual user and service accounts can also present security risks, particularly if privileged. As such, user and service accounts should never be given access to assets directly, but should instead be assigned customized roles. These roles should be granted only the minimum access rights and permissions required to perform a given job. Wikipedia describes the principle of Role Based Access Control (RBAC) quite well here and AWS describes Attribute-based access control (ABAC) here.
If a particular user action is seen as universally risky or unnecessary, a service control policy (SCP) can be used to define a policy that takes precedence over permissions granted by IAM roles, preventing the action.
It is also important to note the difference between IAM policies and S3 bucket policies. IAM policies define what actions (list/read/write) a principal (user/role/resource) can perform against a specific resource (S3/CloudWatch/Lambda). At first glance, bucket policies appear to be very similar as they also allow or deny specific actions that are applied to a principal. The key difference however, is that the rules are confined within the bucket that they are associated with. See the Amazon documentation for more detail here.
IAM and bucket policies should work in harmony to provide security. If there is no applicable policy against an asset, or if an IAM or S3 bucket policy denies access, then access is denied. This is because AWS access operates on the principle of least privilege, where an explicit deny will always trump an explicit allow, and if neither are defined, the decision to grant access will always default to deny. This basically means that for access to be granted, one policy must explicitly allow access, while the other must simply not deny it.
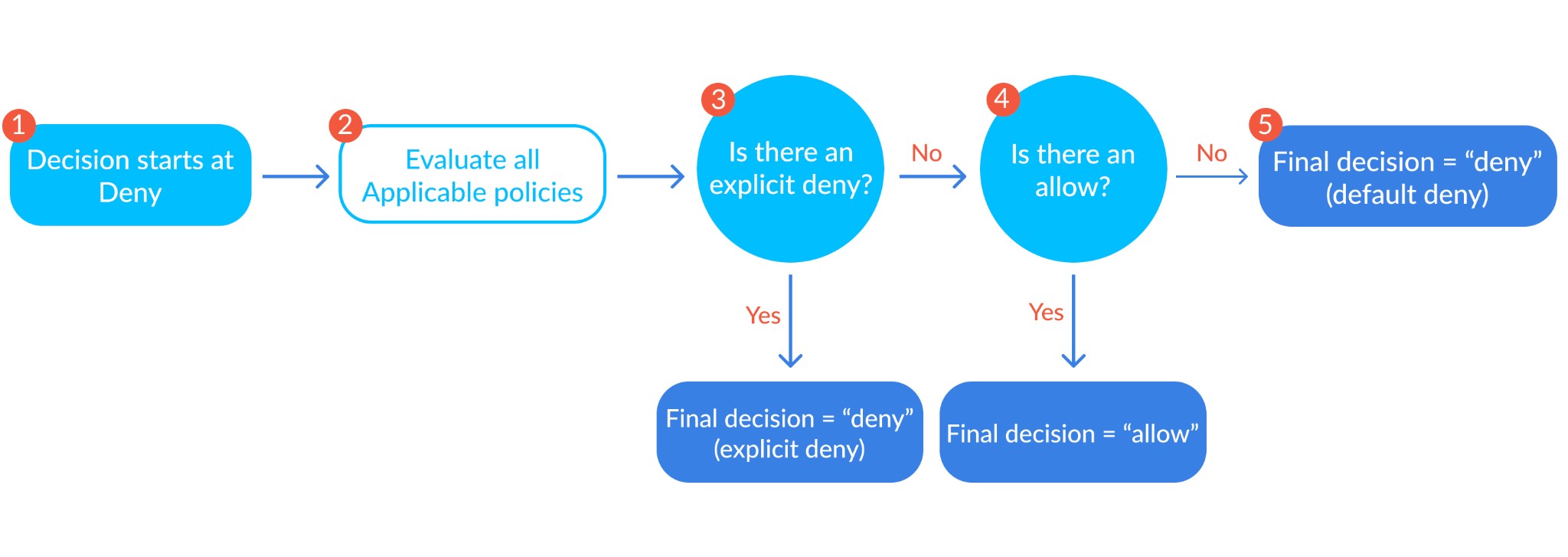
The authorization decision depends on the union of both the IAM policies and S3 bucket policies (source)
Table 1.0 highlights the results of combining an AIM and S3 bucket policy
| AIM policy | S3 bucket policy | Outcome |
| None | none | deny |
| Allow | allow | allow |
| Allow | deny | deny |
| Deny | allow | deny |
| Deny | deny | deny |
Access monitoring
Tagging is an overlooked and underappreciated practice. Tagging assets allows you to quickly categorize and find important or sensitive resources. This is particularly useful for risk analysis exercises and makes the process of a SOC 2, HIPAA, or other compliance audit much easier.
While tagging helps identify and find assets, AWS users should also actively monitor any access to these assets. AWS provides services such as CloudTrail, S3 Server Access Logging and AWS Config, that provide mechanisms to do exactly this:
- CloudTrail provides detailed API tracking for S3 operations at the bucket level. It can be integrated with CloudWatch logs to build reports and generate alarms based on specified API activity
- S3 server access logging allows access to fine grained object-level operations
- AWS Config is a service that can be configured to ensure that CloudTrail is logging data events for all S3 buckets
|
Platform
|
Provisioning Automation |
Security Management |
Cost Management |
Regulatory Compliance |
Powered by Artificial Intelligence |
Native Hybrid Cloud Support
|
|---|---|---|---|---|---|---|
|
AWS Native Tools |
✔
|
✔
|
✔
|
|||
|
CoreStack
|
✔
|
✔
|
✔
|
✔
|
✔
|
✔
|
Object sensitivity & encryption
It’s a phrase used daily by security engineers, but its importance never diminishes – all data should be encrypted in transit and at rest. Encryption in transit can be achieved either through client side encryption and/or the use of SSL/TLS protocols.
With S3, multiple configuration options exist for data at rest. One option is to enable the default bucket encryption, which simply encrypts all incoming objects when stored. AWS actually offers this functionality at no extra charge. This option should be enabled when the bucket is first created, as the encryption will not be applied to any objects stored before this point.
Alternatively, if you do not wish to use default encryption, there is also the option to include encryption metadata with every object storage request. Any S3 HTTP Put request (an instruction to store an object) will be rejected unless the object is encrypted using server-side encryption. See the Amazon documentation for further details, here.
Regardless of encryption, steps should still be taken to classify or categorize data based on sensitivity. Highly sensitive data should be separated from the rest, either physically or logically. You can then use tags and object metadata to describe the files content or purpose. To ensure that you have removed or identified any Personally Identifiable Information (PII), you can use Amazon Macie. Macie is a fully managed service that uses pattern matching and advanced machine learning to discover and protect sensitive data.
Bucket structure
When planning and designing your storage structure you should be aware of bucket limits. By default, you can create up to 100 buckets in each AWS account and this can be increased if absolutely necessary, by submitting a service request. Usually however, a well designed storage plan can avoid the need for additional buckets, as there are no limits to the number of objects that can be stored in or across them.
Poorly designed bucket architecture can result in files or directories being exploited, accidently updated, deleted or just forgotten about, so be careful.
Having unlimited objects allows you to create a scalable directory structure, but remember to use logical namespacing that allows easy searching and bucket analysis.
If planning to use the bucket as a data source for advanced analysis and reporting, make sure to structure the data optimally for your chosen solution. For example, if using Amazon Athena, the official documentation has recommendations for folder partitioning, file format, file size and even file content format.
Finally, remember that once a bucket has been created, its name and associated region cannot be changed later, so it’s important to be accurate at the beginning.
The human touch
Despite the exponential growth of third party and AWS managed services designed to protect data, it’s crucial that both your engineering and security teams get involved with the design, implementation and review of your S3 solution.
Buckets and their complete configuration should be designed and stored as code. This practice, known as Infrastructure as Code, is a revolutionary way of managing your organization's infrastructure, using a descriptive model. Relying on manual configuration alone can lead to inconsistencies that are hard to identify and could lead to exploitation (think of Twilio and Sega). Infrastructure as code on the other hand, is designed to allow developers to rapidly and reliably generate the same environment, time and time again.
There are also other advantages to infrastructure as code. Code can be version controlled (just like regular software), effectively providing snapshots of infrastructure at any given point in time. Code can also undergo peer review. Should a developer require a new S3 bucket, or a change to an existing bucket policy, the required actions can be defined in code. This can then be sent to other developers, or a security team, for review. This is a proven way of sharing knowledge, improving code quality and reducing the number of errors that make it to production systems.
AWS CloudFormation lets you model, provision, and manage resources by treating infrastructure as code (source)
Finally, security teams should conduct regular, manual and thorough inspection of all bucket policies. They should then verify that any monitoring and reporting, disaster recovery or business continuity processes are actively followed and working as expected.
|
Platform
|
Provisioning Automation |
Security Management |
Cost Management |
Regulatory Compliance |
Powered by Artificial Intelligence |
Native Hybrid Cloud Support
|
|---|---|---|---|---|---|---|
|
AWS Native Tools |
✔
|
✔
|
✔
|
|||
|
CoreStack
|
✔
|
✔
|
✔
|
✔
|
✔
|
✔
|
Conclusion
Despite the many ways that S3 has been exploited in the past, it is not a particularly risky service to use. As we have seen, there are a number of steps that users can take to ensure that data is secure. This effort is ultimately worth it, given the level of functionality and flexibility that S3 has to offer. In fact, most of the best practices that we have discussed are trivial to implement and are likely to have saved some high profile companies a lot of embarrassment, or worse. Even the more complex and manual controls can be implemented at an early stage, by incorporating them into your development lifecycle and establishing well defined processes. You can then leverage the many AWS services to reduce the complexity of managing and monitoring them manually.